Contact
Testez Negent
sur vos documents.
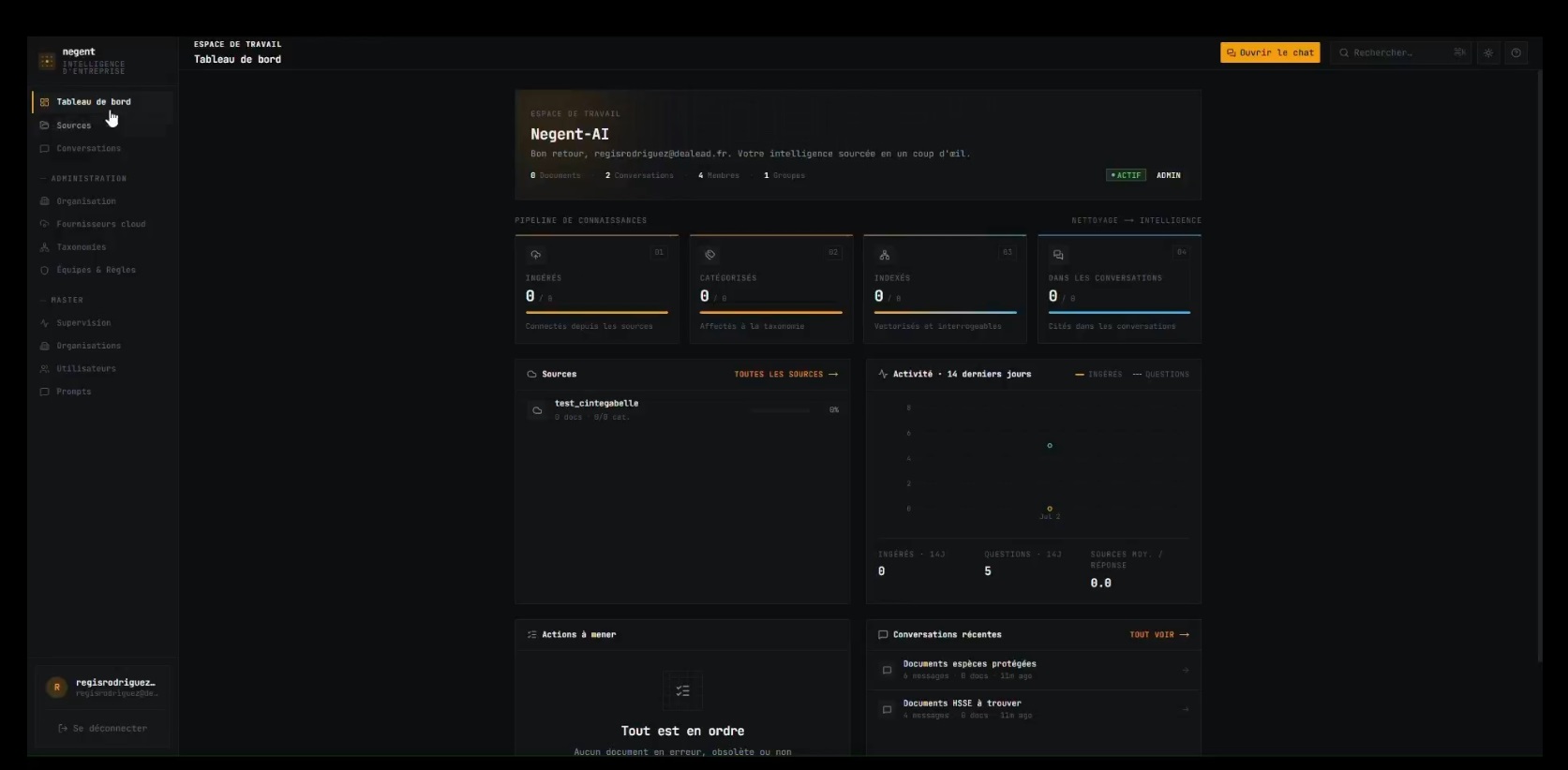
Testez Negent Clean en direct, sur vos propres documents. En moins de 10 minutes, nous ingérons une centaine de documents, les fiabilisons, les structurons et établissons leurs liens — puis vous les interrogez, séance tenante. Avant toute décision.
Voir la démo · 4 min
Première réponse sous 24h
Un expert Negent vous contacte pour cadrer votre périmètre et organiser le test sur vos propres documents.
Test sur vos documents
En direct avec vous : une centaine de vos documents ingérés, fiabilisés, structurés et reliés entre eux — puis interrogeables, en moins de 10 minutes.
NDA disponible
Vos documents restent confidentiels : un accord de confidentialité peut être signé dès le premier contact.